
Paddle Lite: A Comprehensive Introduction
Overview
Paddle Lite is a high-performance, lightweight, flexible, and easily extendable deep learning inference framework. It is designed to support a wide range of hardware platforms, including mobile devices, embedded systems, and edge devices.
Currently, Paddle Lite is extensively used in internal Baidu projects and has also been successfully adopted by numerous external users and enterprises for production tasks.
Quick Start Guide
Deploying models with Paddle Lite across different end devices for high-performance inference tasks involves a straightforward process:
1. Model Preparation
Paddle Lite directly supports models derived from the PaddlePaddle deep learning framework. These models are saved using the save_inference_model API. If your model originates from frameworks like Caffe, TensorFlow, or PyTorch, you can convert it to the PaddlePaddle format using the X2Paddle tool.
2. Model Optimization
The Paddle Lite framework features advanced acceleration and optimization strategies, including quantization, subgraph fusion, and kernel selection. These optimizations result in lighter models that require fewer resources and execute at faster speeds. These enhancements can be achieved using the opt tool provided by Paddle Lite. The opt tool also analyzes and displays the operator information within the model and assesses Paddle Lite's compatibility across various hardware platforms. After obtaining a PaddlePaddle format model, it is generally recommended to optimize it using this tool. For details on downloading and using the opt tool, refer to Model Optimization Methods.
3. Download or Compile
Paddle Lite offers official release prediction libraries for Android, iOS, x86, and macOS platforms. It is recommended to download the precompiled Paddle Lite libraries directly or obtain the latest precompiled library from the Release notes.
For those interested in source compilation, Paddle Lite supports building in various environments. To avoid the complexities of setting up the environment, using Docker for a uniform compilation environment is suggested. Alternatively, based on the host and target device's CPU architecture and operating system, you can find relevant guides to set up and compile from source in the source compilation section.
4. Prediction Examples
Paddle Lite offers APIs in C++, Java, and Python, along with complete usage examples for each:
These examples help users quickly understand usage methods and integrate them into their own projects.
Moreover, for different hardware platforms, complete examples are provided:
- Android apps (Image Classification, Object Detection, Mask Detection, Face Keypoints Detection, Human Segmentation)
- iOS apps
- Linux apps
- Other platforms like Arm, x86, OpenCL, Metal, Huawei Kirin NPU, Huawei Ascend NPU, Kunlunxin XPU, Kunlunxin XTCL, Qualcomm QNN, Cambricon MLU, and more.
Key Features
- Multi-Platform Support: Covers Android, iOS, embedded Linux devices, Windows, macOS, and Linux hosts.
- Multi-Language Support: Available in Java, Python, and C++.
- Lightweight and High Performance: Optimized for machine learning on mobile devices, supports model and binary file size compression, efficient inference, and reduced memory consumption.
Continuous Integration
Paddle Lite ensures continuous integration across various systems including x86 Linux, ARM Linux, Android (GCC/Clang), and iOS, maintaining high build quality across these platforms.
Architectural Design
The architecture of Paddle Lite is meticulously designed to support multiple hardware and platforms, enhance mixed execution capability across various hardware for a single model, and implement multiple layers of performance optimization, alongside lightweight design for end-side applications.
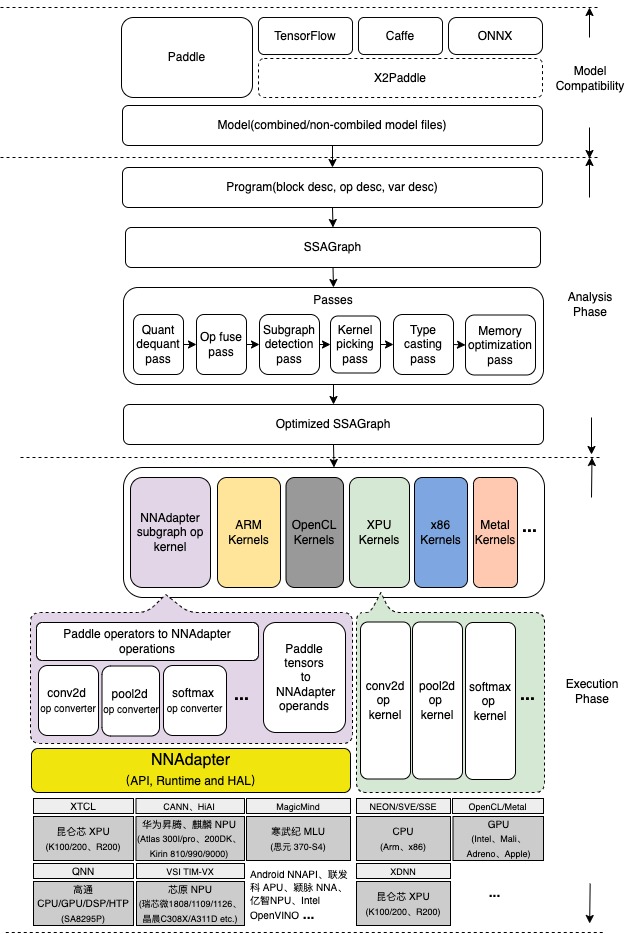
Further Learning and Resources
For those interested in diving deeper into Paddle Lite, here are some additional resources:
Documentation and Examples
- Complete documentation: Paddle Lite Documentation
- API Documentation for C++, Java, Python, and CV Image Processing.
- Example projects: Paddle-Lite-Demo
Key Technologies
- Model Quantization with both Static and Dynamic offline quantization techniques.
- Debugging and Analysis Tools: Profiling and Performance Analysis
- Mobile Model Training: On the go
- Pre-trained Model Library: Explore and download models from PaddleHub
- NNAdapter for AI hardware adaptation: Discover More
Contributing and Support
- Contribution Guide: Participate in Paddle Lite development by checking the Developer Share Documentation.
For more information on FAQs and support, visit the FAQ section or get in touch via community channels provided.
Communication and Feedback
Engage with the community through the AIStudio training platform, GitHub Issues, and join technical discussion groups on WeChat or QQ for deeper engagement.
Licensing
Paddle Lite is licensed under Apache-2.0 license.