
Versteht die Aufgabe
Der Agent verbindet Ihre Vorgaben mit den Quellen, statt nur eine Ein-Klick-Konvertierung auszuführen.
Fügen Sie die passenden Unterlagen hinzu (Bewerbungsunterlagen und Stellenkriterien) und beschreiben Sie Ihr Ziel. Sie erhalten einen konsistenten belegten Kandidatenvergleich, das Sie prüfen und weiterbearbeiten können.
Stellen Sie Bewerbungsunterlagen und Stellenkriterien und die für diese Aufgabe wichtigen Angaben bereit.
Der Agent prüft die Quellen, folgt Ihren Vorgaben und erstellt einen konsistenten belegten Kandidatenvergleich.
Prüfen Sie das Ergebnis, verlangen Sie Änderungen im selben Gespräch und laden Sie die finale Fassung herunter.
Öffnen Sie die vollständige Datei oder sehen Sie sich unten die wichtigsten Seiten an.
Vollständige Datei öffnen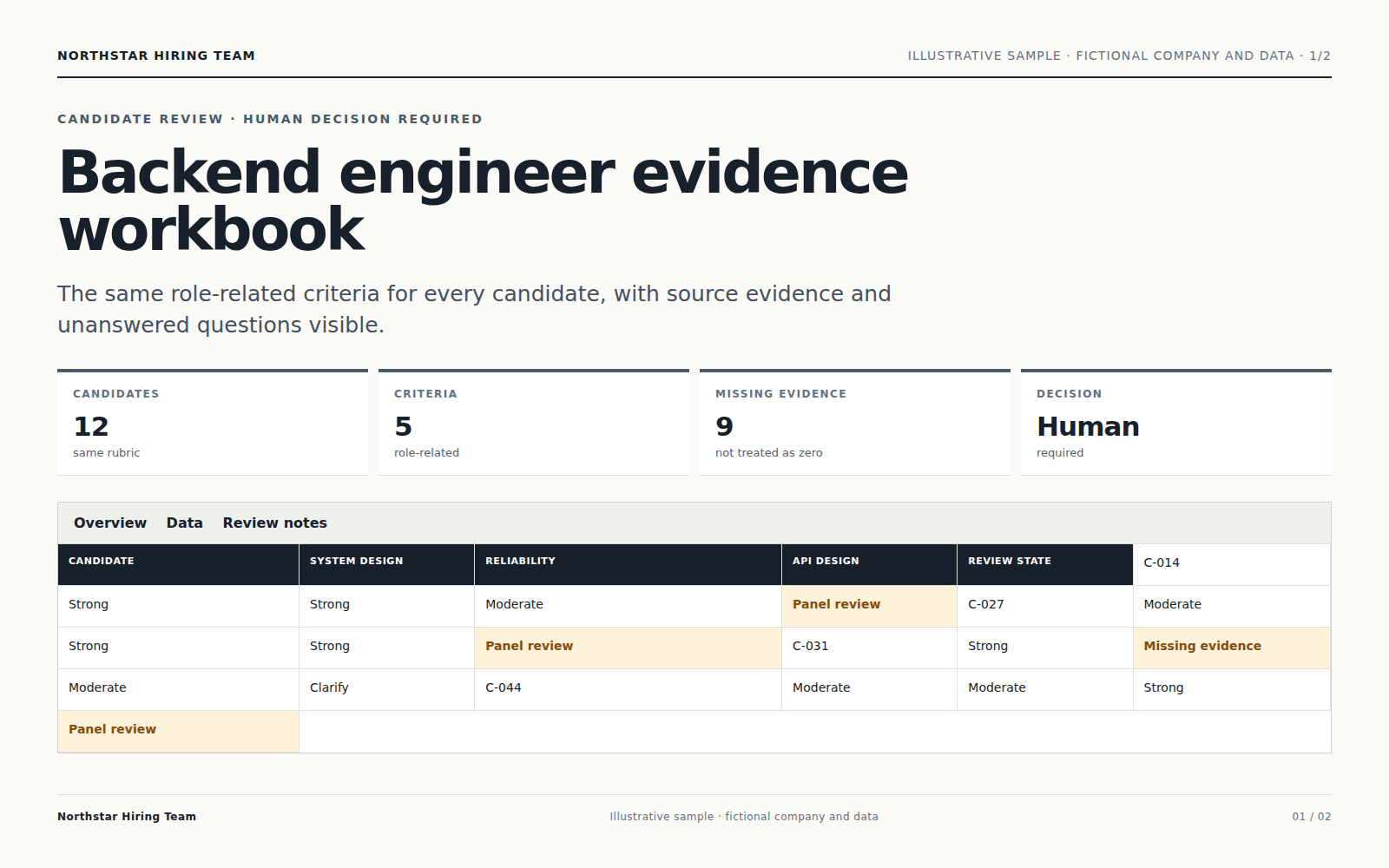

Der Agent verbindet Ihre Vorgaben mit den Quellen, statt nur eine Ein-Klick-Konvertierung auszuführen.
Wichtige Aussagen bleiben mit Ihrem Material verknüpft; Unsicherheiten werden zur Prüfung markiert.
Sie erhalten einen konsistenten belegten Kandidatenvergleich, die Sie prüfen, herunterladen und weiter verbessern können.
Beginnen Sie mit Bewerbungsunterlagen und Stellenkriterien und ergänzen Sie Zielgruppe, Ziel, Vorgaben und gewünschtes Format.
Er liest die Quellen, plant die Arbeit, nutzt passende Werkzeuge und erstellt einen konsistenten belegten Kandidatenvergleich zur Prüfung.
Ja. Prüfen Sie das Ergebnis und lassen Sie sich einzelne Punkte erklären oder ändern.
Ja. Passen Sie im selben Gespräch Schwerpunkt, Formulierung, Umfang oder Format weiter an.
Arbeiten Sie mit demselben Material weiter, ohne Dateien zwischen Produkten zu verschieben.
Für Lebenslauferstellung: Ihre Berufserfahrung oder einen bestehenden Lebenslauf hinzufügen. Der Vecbase-Agent erstellt einen ATS-lesbaren Lebenslauf zum Prüfen und Bearbeiten.
Für Stellenbeschreibung: ein Recruiting-Briefing, Teamnotizen oder eine vorhandene Anzeige hinzufügen. Der Vecbase-Agent erstellt eine klare veröffentlichungsfertige Stellenbeschreibung zum Prüfen und Bearbeiten.
Vecbase
Fügen Sie für Lebenslauf-Screening Bewerbungsunterlagen und Stellenkriterien hinzu, nennen Sie die wichtigsten Anforderungen und lassen Sie den Vecbase-KI-Agenten einen konsistenten belegten Kandidatenvergleich erstellen. Anschließend können Sie alles prüfen und weiterbearbeiten.
