
理解任务,不只是读取文件
Agent 会对所有候选人应用同一标准,并展示匹配证据、信息缺口和不确定性供人工复核。
添加 JD 和候选人简历。Vecbase Agent 会一致应用评价标准、引用每项比较的来源、说明不确定性,并把最终决定留给人。
上传简历,同时提供职位描述和与岗位相关的评价标准,或说明最重要的岗位结果。
Agent 会对所有候选人应用同一标准,并展示匹配证据、信息缺口和不确定性供人工复核。
获得便于安排后续沟通的对比报告,但最终招聘决定仍由人作出。
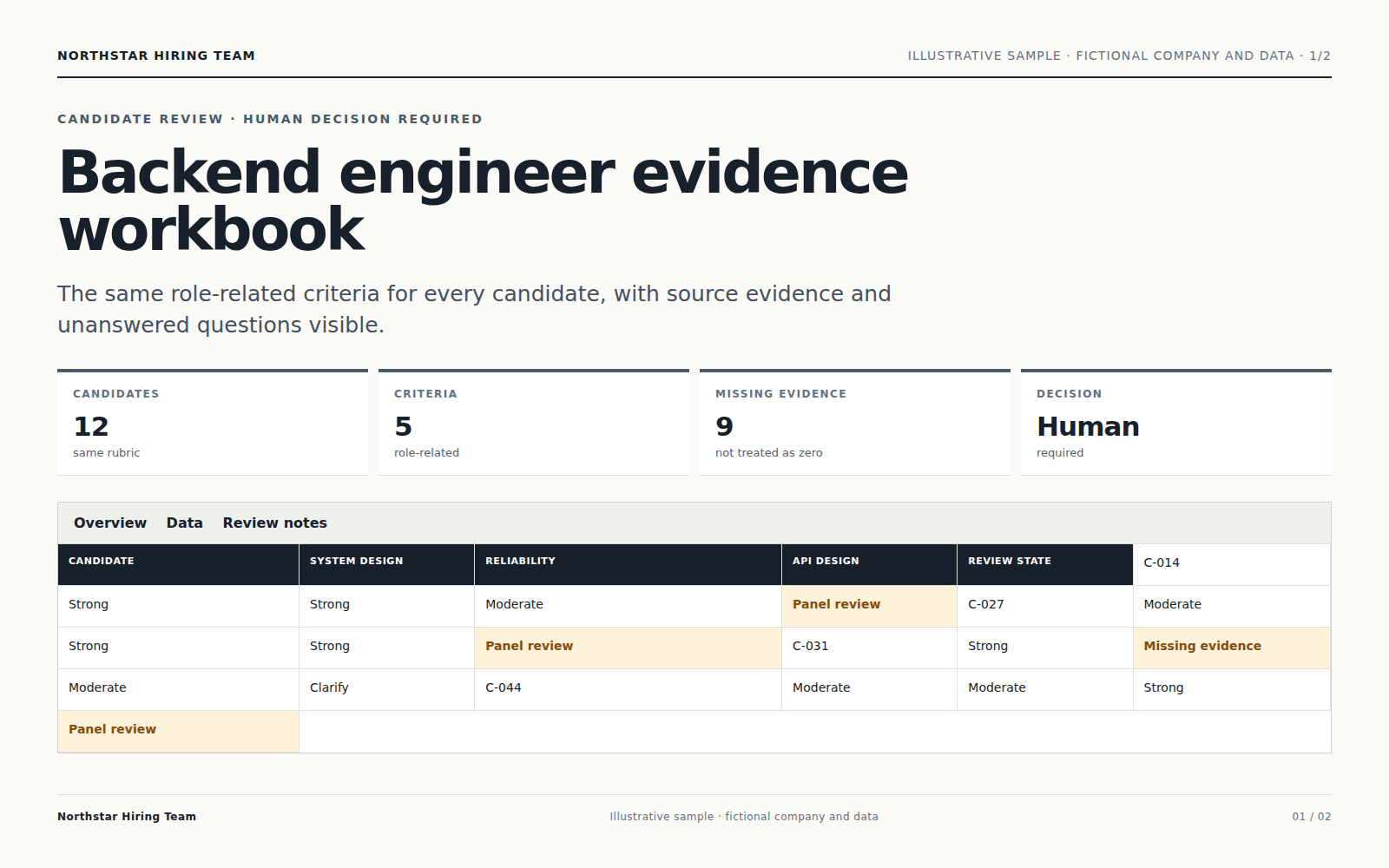

Agent 会对所有候选人应用同一标准,并展示匹配证据、信息缺口和不确定性供人工复核。
评分会引用简历证据,不推断受保护特征,也不会把缺失信息直接当成负面事实。
获得便于安排后续沟通的对比报告,但最终招聘决定仍由人作出。
上传简历,同时提供职位描述和与岗位相关的评价标准,或说明最重要的岗位结果。
Agent 会对所有候选人应用同一标准,并展示匹配证据、信息缺口和不确定性供人工复核。
评分会引用简历证据,不推断受保护特征,也不会把缺失信息直接当成负面事实。
可以。你可以在同一段对话中调整重点、文字、范围或格式。获得便于安排后续沟通的对比报告,但最终招聘决定仍由人作出。
