analisi delle interviste con un agente Vecbase
Aggiungi i materiali necessari (registrazioni, trascrizioni o appunti delle interviste) e descrivi ciò che ti serve. Otterrai insight di prodotto sostenuti da citazioni reali, che potrai verificare e perfezionare prima di scaricare.
Vecbase 1.0 Lite

- 1Aggiungi registrazioni
- 2Descrivi il risultato
- 3Invia
Un risultato finito in tre passaggi
- 1
Aggiungi il contesto giusto
Fornisci registrazioni, trascrizioni o appunti delle interviste e i dettagli importanti per questa attività.
- 2
Lascia lavorare l’Agent
L’Agent esamina le fonti, segue i requisiti e prepara insight di prodotto sostenuti da citazioni reali.
- 3
Verifica e perfeziona
Controlla il risultato, chiedi modifiche nella stessa conversazione e scarica la versione finale.
Guarda il risultato reale
Apri il file completo o consulta le pagine principali qui sotto.
Apri il file completo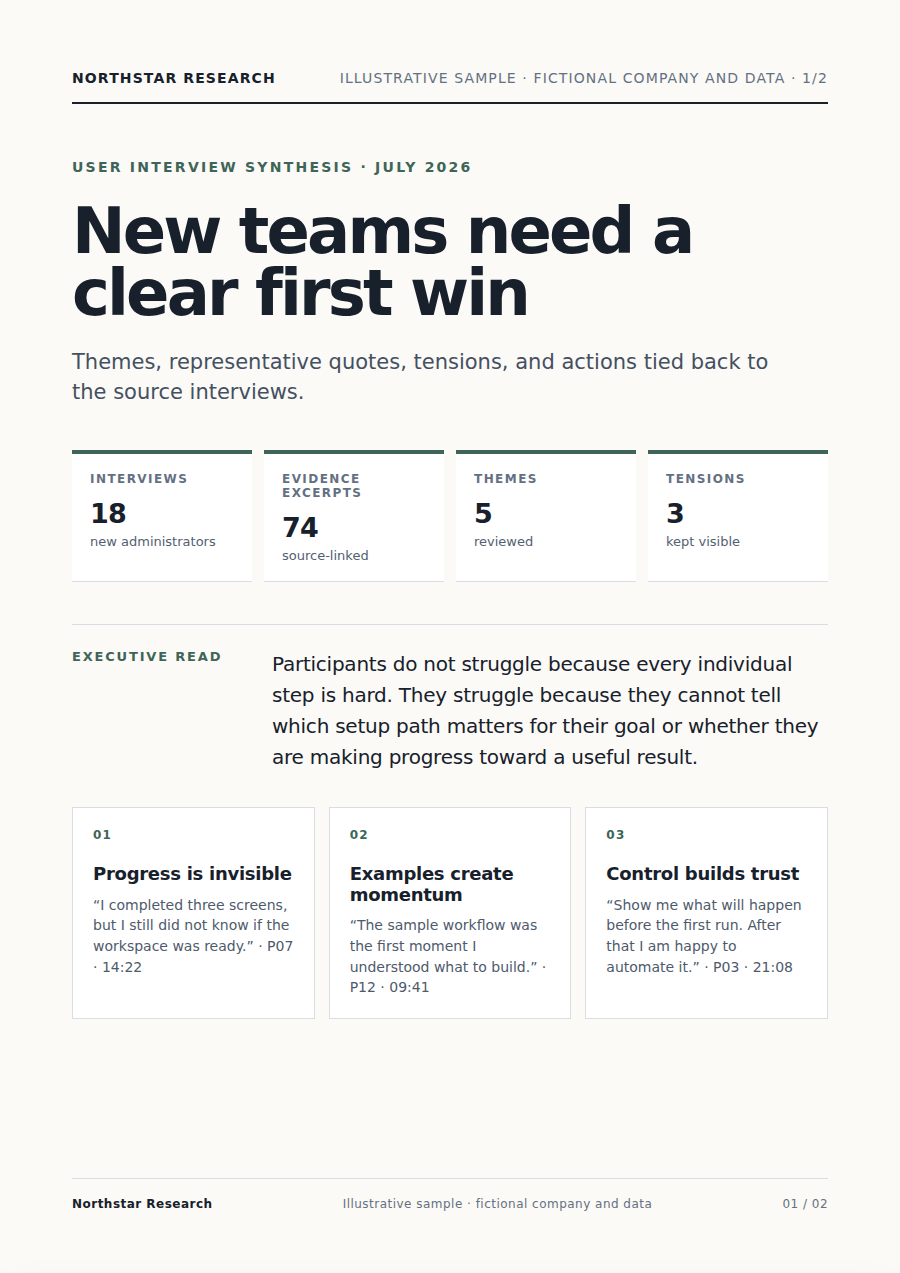

Domande prima di iniziare
Cosa devo fornire per analisi delle interviste?
Inizia con registrazioni, trascrizioni o appunti delle interviste e aggiungi pubblico, obiettivo, vincoli e formato desiderato.
Come svolge il lavoro l’Agent?
Legge le fonti, pianifica il lavoro, usa gli strumenti adatti e prepara insight di prodotto sostenuti da citazioni reali da verificare.
Posso controllare il risultato?
Sì. Verifica il risultato e chiedi spiegazioni o modifiche prima di usarlo.
Posso continuare a modificarlo?
Sì. Nella stessa conversazione puoi cambiare priorità, testo, ambito o formato.
Strumenti correlati
Continua a lavorare sugli stessi materiali senza spostare file tra prodotti diversi.
verbale di riunione
Per verbale di riunione, aggiungi una registrazione, una trascrizione o gli appunti della riunione. L’agente Vecbase prepara un verbale chiaro con decisioni e attività da verificare e modificare.
analisi dei feedback clienti
Per analisi dei feedback clienti, aggiungi feedback, ticket o dati di sondaggio. L’agente Vecbase prepara un rapporto con temi ed evidenze da verificare e modificare.
controllo qualità delle chiamate
Per controllo qualità delle chiamate, aggiungi registrazioni e una griglia di qualità. L’agente Vecbase prepara un audit con punteggio ed evidenze temporali da verificare e modificare.

Vecbase
Inizia ora: analisi delle interviste
Per analisi delle interviste, aggiungi registrazioni, trascrizioni o appunti delle interviste, indica ciò che conta di più e lascia che l’agente IA di Vecbase prepari insight di prodotto sostenuti da citazioni reali, che potrai verificare e perfezionare.