
理解任务,不只是读取文件
Agent 会整理口播脚本、处理角色与读音,并调整节奏和音量,让成品清楚易听。
添加脚本并说明角色、节奏和语气。Vecbase Agent 会整理读音与时间,再把已获授权的声音和音乐混合成可复核结果。
填写脚本,并说明受众、语气、节奏、角色、读音和使用场景;需要时可附参考素材。
Agent 会整理口播脚本、处理角色与读音,并调整节奏和音量,让成品清楚易听。
获得成品音频和制作脚本,并可继续修改单句、节奏或表达方式。
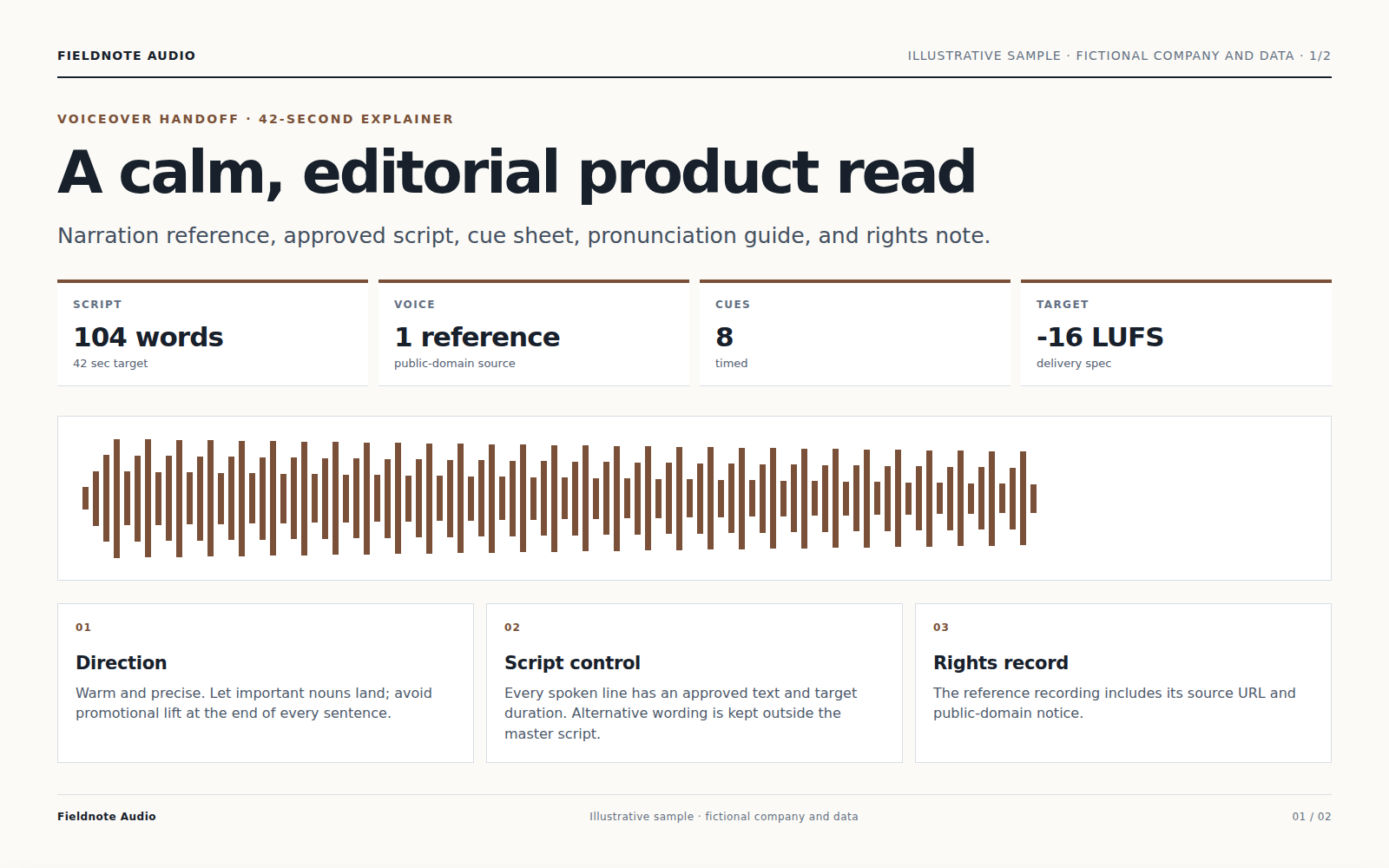
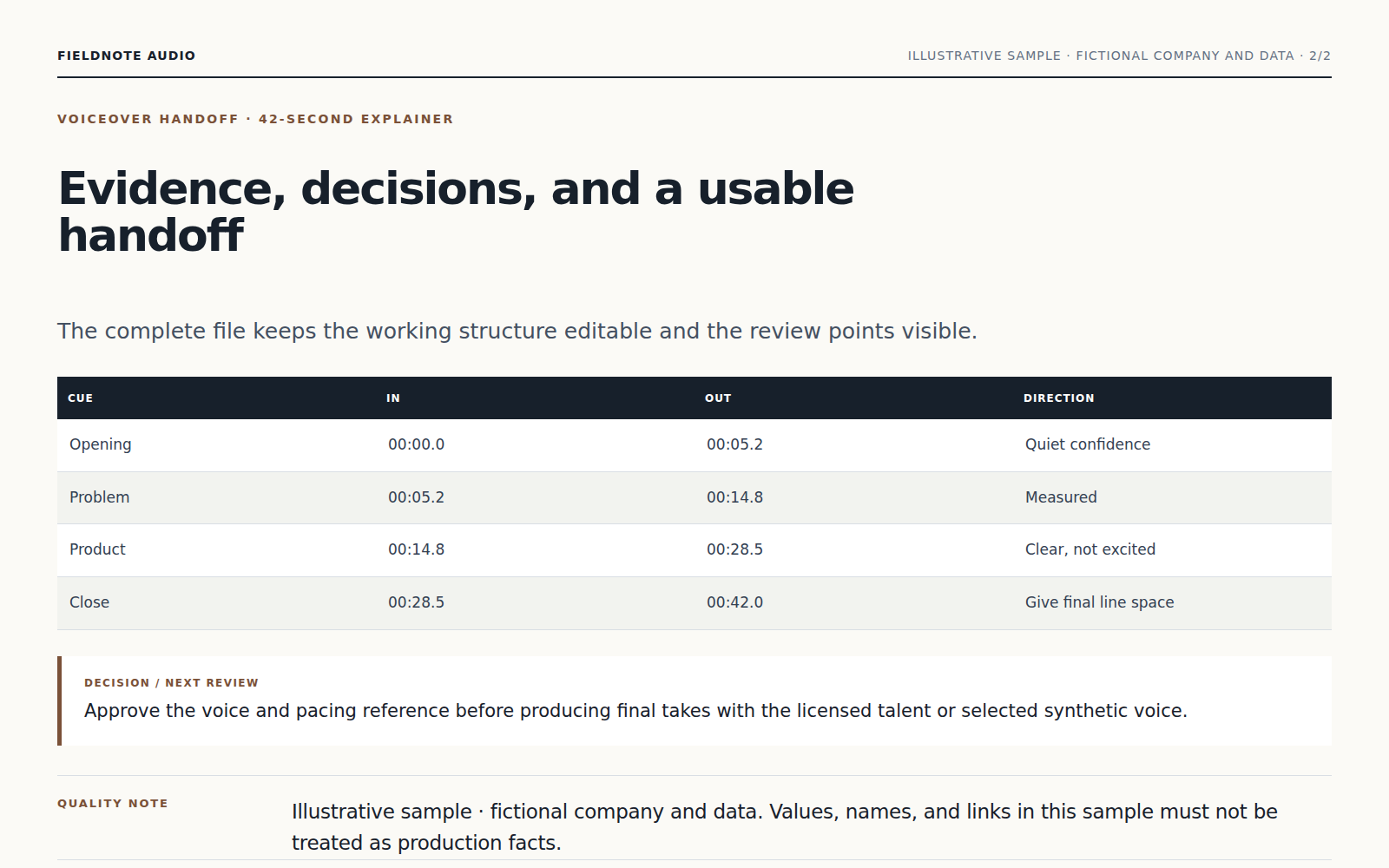
Agent 会整理口播脚本、处理角色与读音,并调整节奏和音量,让成品清楚易听。
声音和原始素材只会在你确认的授权范围内使用;Agent 不会默认你已取得许可或所有权。
获得成品音频和制作脚本,并可继续修改单句、节奏或表达方式。
填写脚本,并说明受众、语气、节奏、角色、读音和使用场景;需要时可附参考素材。
Agent 会整理口播脚本、处理角色与读音,并调整节奏和音量,让成品清楚易听。
声音和原始素材只会在你确认的授权范围内使用;Agent 不会默认你已取得许可或所有权。
可以。你可以在同一段对话中调整重点、文字、范围或格式。获得成品音频和制作脚本,并可继续修改单句、节奏或表达方式。
同一份材料可以继续处理,不用在多个产品之间反复搬文件。
