
理解任务,不只是读取文件
Agent 会转写语音、安排易读断句与时间轴、结合上下文翻译,并检查镜头切换处的连贯性。
添加视频并选择语言。Vecbase Agent 会制作易读时间轴、按需翻译、标出不确定语句,并交付可以继续编辑的字幕文件。
上传视频,并说明原语言、如需翻译时的目标语言、字幕风格,以及人名或专有术语。
Agent 会转写语音、安排易读断句与时间轴、结合上下文翻译,并检查镜头切换处的连贯性。
下载可编辑 SRT 或 VTT 字幕,并可继续修正人名、文字、时间轴或翻译选择。
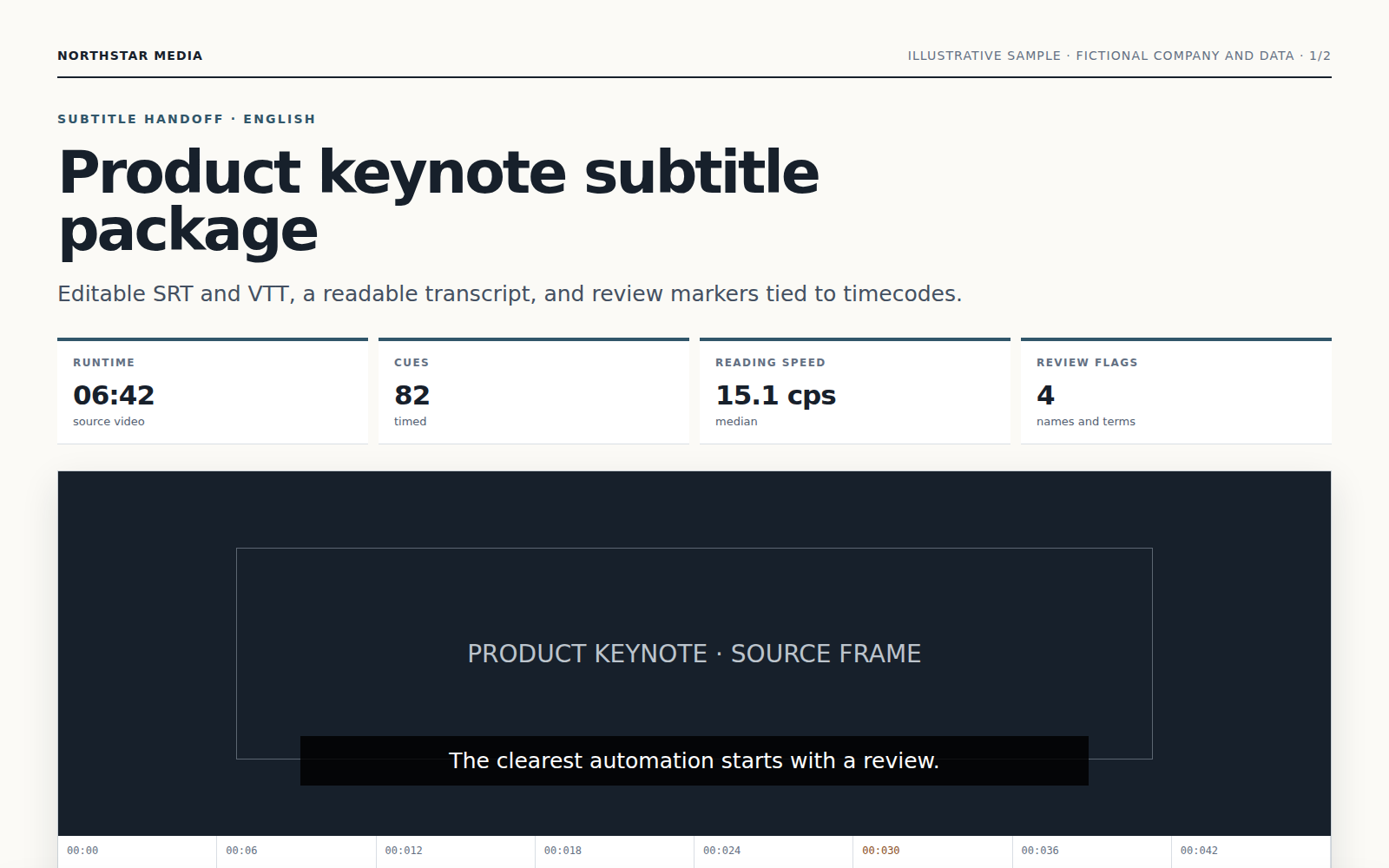

Agent 会转写语音、安排易读断句与时间轴、结合上下文翻译,并检查镜头切换处的连贯性。
听不清的语音、不确定的人名和低置信度语句会带时间点标记,不会被静默猜测。
下载可编辑 SRT 或 VTT 字幕,并可继续修正人名、文字、时间轴或翻译选择。
上传视频,并说明原语言、如需翻译时的目标语言、字幕风格,以及人名或专有术语。
Agent 会转写语音、安排易读断句与时间轴、结合上下文翻译,并检查镜头切换处的连贯性。
听不清的语音、不确定的人名和低置信度语句会带时间点标记,不会被静默猜测。
可以。你可以在同一段对话中调整重点、文字、范围或格式。下载可编辑 SRT 或 VTT 字幕,并可继续修正人名、文字、时间轴或翻译选择。
