
理解任务,不只是读取文件
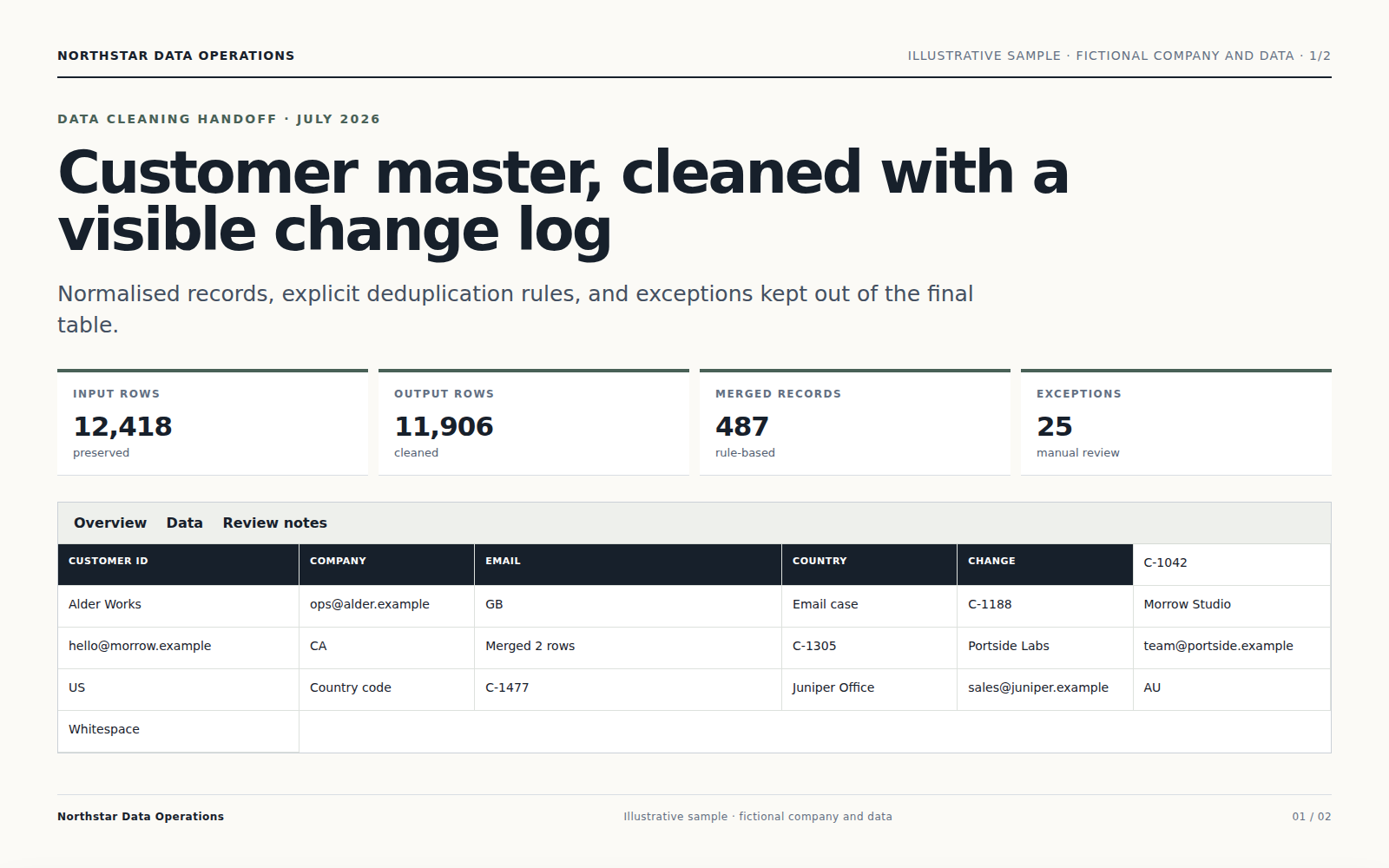
Agent 会分析各列,按明确规则清洗,并把可安全修正的内容与需要你判断的记录分开。
上传杂乱的数据导出。Vecbase Agent 会先识别问题,再按明确规则处理,交付清洗结果、变更记录和可复用脚本。
上传 CSV,并说明目标字段结构、去重规则、日期和数字格式,以及绝不能改动的字段。
Agent 会分析各列,按明确规则清洗,并把可安全修正的内容与需要你判断的记录分开。
下载清洗后的 CSV、变更记录和例外清单,原始文件保持不变。
Agent 会分析各列,按明确规则清洗,并把可安全修正的内容与需要你判断的记录分开。
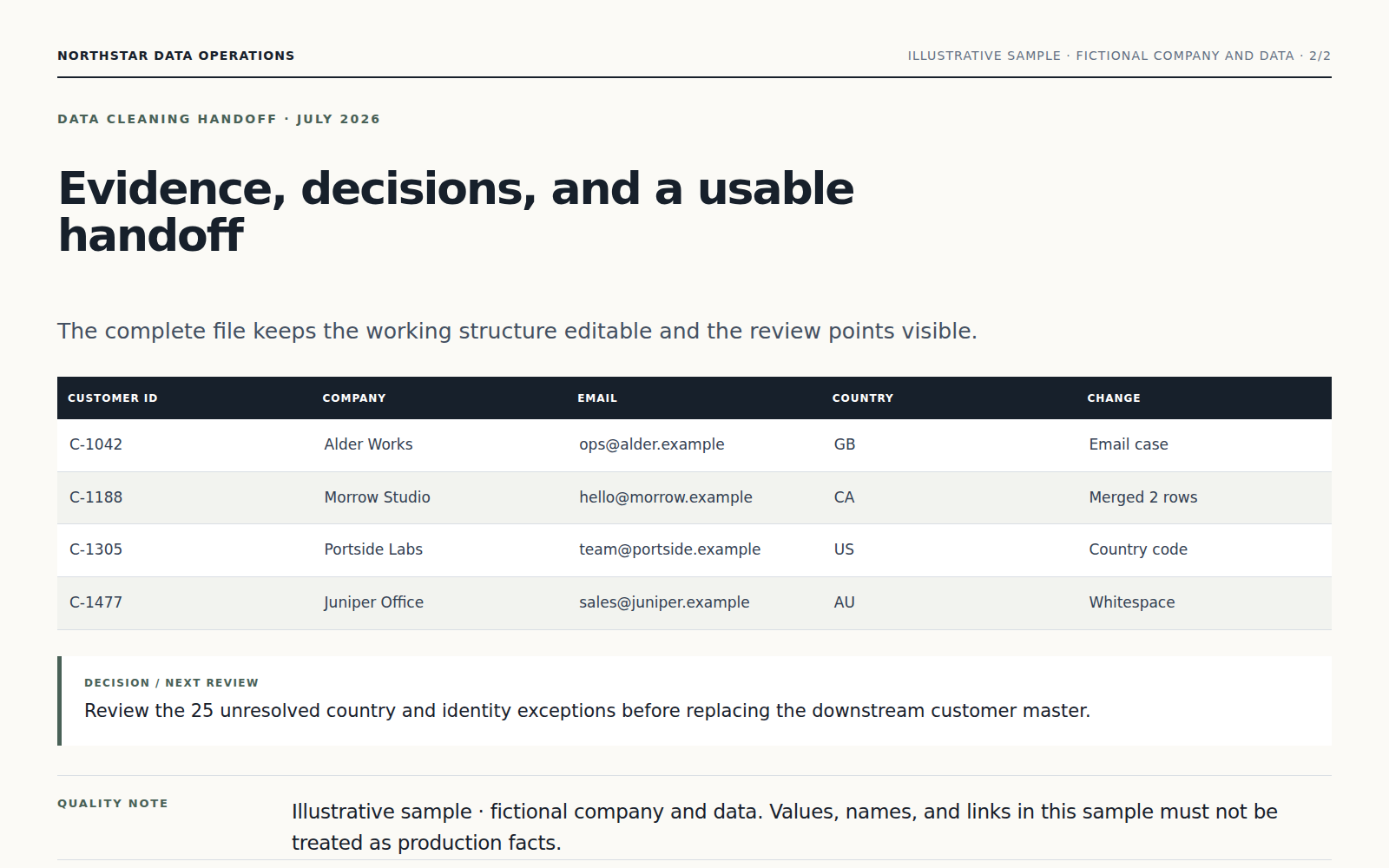
删除、合并或改写的记录都会统计并说明,不确定变更不会悄悄混入结果。
下载清洗后的 CSV、变更记录和例外清单,原始文件保持不变。
上传 CSV,并说明目标字段结构、去重规则、日期和数字格式,以及绝不能改动的字段。
Agent 会分析各列,按明确规则清洗,并把可安全修正的内容与需要你判断的记录分开。
删除、合并或改写的记录都会统计并说明,不确定变更不会悄悄混入结果。
可以。你可以在同一段对话中调整重点、文字、范围或格式。下载清洗后的 CSV、变更记录和例外清单,原始文件保持不变。
